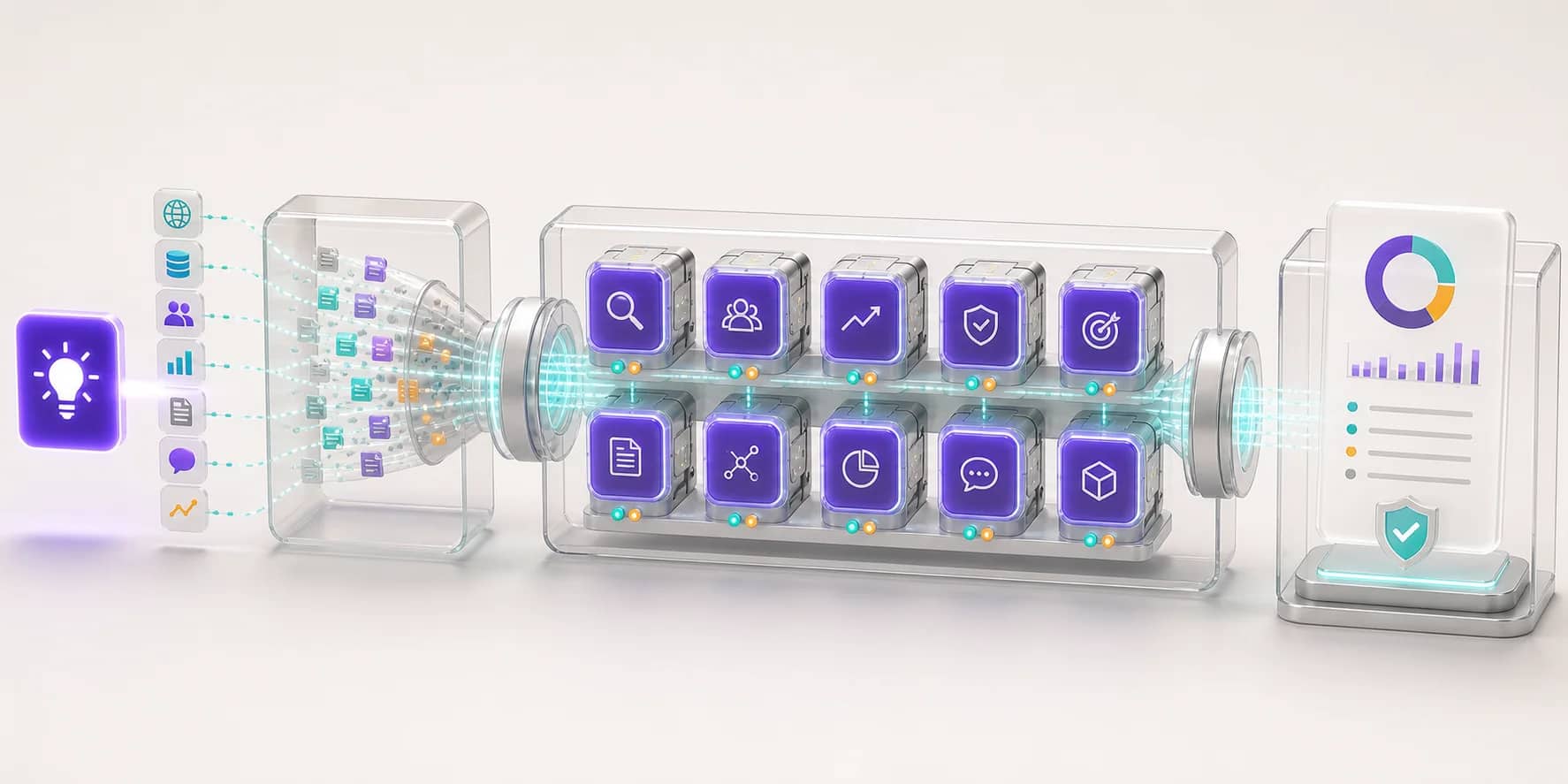
Key takeaways
- Parallel agents: 10 specialized AI agents run at once, each pulling real-time data from 50+ live sources.
- Cross-validation: Every result runs across multiple AI models, the median score gets picked and outliers get discarded.
- Output: A 15-section report with sourced findings in about 6 minutes.
Preuve AI (formerly Test Your Idea)'s Deep Analysis is an agentic RAG pipeline -a compound AI system where 10 specialized agents work in parallel, pulling real-time data from 50+ live sources and cross-validating results across multiple AI models from different providers. Unlike single-prompt tools, it retrieves real market data before any AI touches your idea.
You type in your startup idea. About 6 minutes later, you get a 15-section report with sourced competitor data, market sizing, community demand signals, and a viability score out of 100. Every number links to its source. If you are still choosing between ideas, start with the startup idea generator to shortlist directions before you run a full scan.
What actually happens during those 6 minutes?
Most "AI validation tools" follow the same basic pattern: your idea goes to one AI model, the model generates whatever sounds plausible, and you get back a nice-looking PDF with zero sources. According to the Vectara Hallucination Leaderboard, even top-performing models hallucinate in 1.5% to 8% of responses -and rates climb significantly higher for complex analytical tasks like market sizing. So I built something that doesn't guess.
Will your idea survive the market?
Preuve AI runs 10 agents against live market data and links every claim to a source. Free analysis in 60 seconds.
Why I Built Three Layers, Not One Prompt
The Deep Analysis doesn't send your idea to an AI and ask "what do you think?" I designed it in three distinct layers, each one targeting a specific failure mode:
- Real-time research - pulling live data from the actual web before any AI touches your idea
- Multi-agent analysis - 10 specialized agents each working on a different dimension of viability
- Cross-validation - multiple AI models analyze the same data, and I pick the median result
This was the first architecture decision I made and the one I'm most stubborn about. Let me break each one down.
Layer 1: Real-Time Research (Before AI Touches Anything)
Before any AI model analyzes your idea, the pipeline pulls live data from over 50 sources. This is non-negotiable. I refuse to let AI "imagine" your competitive landscape.
What gets fetched in real-time:
- Market intelligence -TAM/SAM/SOM estimates, industry reports, funding round data from financial databases
- Competitor discovery -scraped from G2, Capterra, Product Hunt, Alternative.to, and the open web. Real companies, not hallucinated names.
- Community signals -Reddit threads, Indie Hackers posts, Hacker News discussions, Quora answers. Real people talking about the problem your idea solves.
- Financial benchmarks -customer acquisition costs, revenue comparables, and funding data from similar companies
- Search trends -real-time interest data showing whether demand for your space is growing, flat, or declining
What is RAG (Retrieval-Augmented Generation)?
RAG is an AI architecture where the system retrieves real-world data before generating any analysis. Instead of asking an AI "what do you know about this market?", I fetch the actual data first, then feed it to the AI for analysis. The AI doesn't make up market data -it analyzes market data I actually found. Research from Lewis et al. (2020) showed that RAG architectures significantly reduce hallucinations by grounding AI output in retrieved facts. That's exactly why I chose this architecture from day one.
All research gets cached. If anything fails mid-pipeline -a data source times out, an API has a bad moment -the system resumes from the last checkpoint instead of starting over. I built this to be resilient, not fragile.

Layer 2: 10 Specialized AI Agents Working in Parallel
Once the real data is in, 10 specialized agents analyze it simultaneously. I didn't build one generic "analyze everything" prompt. I built 10 domain experts:
| # | Agent | What It Does |
|---|---|---|
| 1 | Market Analyst | Sizes your total, serviceable, and obtainable market using live financial data |
| 2 | Competitor Intelligence | Maps the competitive landscape with real pricing, features, and funding rounds |
| 3 | Community Demand Analyst | Quantifies demand signals from Reddit, forums, and social platforms |
| 4 | Business Model Architect | Builds your business canvas with unit economics and key assumptions |
| 5 | Go-to-Market Strategist | Designs your launch plan and growth channels based on what works in your space |
| 6 | Financial Modeler | Projects revenue, costs, and break-even timelines with benchmarked assumptions |
| 7 | Risk Assessor | Identifies the specific assumptions that could kill your idea |
| 8 | Validation Scorer | Aggregates all signals into a 0-100 viability score |
| 9 | Action Planner | Creates your prioritized next-steps playbook with specific tasks |
| 10 | Executive Synthesizer | Distills everything into an investor-ready summary |
Each agent receives the same research data but focuses entirely on its own domain. A market sizing agent asks different questions from the same competitor data than a risk assessor does. That's the point - you get 11 focused sections instead of one generic wall of text.
Because they run in parallel, 10 agents don't take 10x longer. They all finish in roughly the same time as one, which is how I compress what would otherwise be days of research into about 6 minutes.
Layer 3: Cross-Validation Across Multiple Models
This is the layer I'm most proud of, and from what I can tell, the one no competitor has replicated.
I don't run your analysis through one AI model once. I run multiple parallel analyses across different AI providers, each producing its own independent score and report, and then I take the median.
Why the median matters:
Any single AI run can hallucinate, over-estimate, or have a bad day. If one run says your TAM is $2 billion and another says $58 billion, the median keeps you grounded. This is the same principle behind ensemble methods in machine learning -multiple models beat a single shot, every time.
This approach is well-studied. Research from "More Agents Is All You Need" (2024) showed that LLM performance scales with the number of instances running in parallel, especially on harder tasks. I discovered why firsthand: early on, the same idea could score 45 on one run and 72 on another. Same idea, same data, wildly different results. Running multiple analyses and picking the median eliminated that variance almost entirely.
If any model returns garbage -malformed data, obvious hallucinations, or a timeout -it gets dropped and the median is calculated from the remaining results. I built this to degrade gracefully, not fail catastrophically.

The Full Pipeline: 8 Steps in 6 Minutes
You submit your idea
Plus optional target market, known competitors, and context
Market category resolved
Deterministic classification so every run starts from the same foundation
Real-time data fetched
50+ sources queried in parallel: competitors, community signals, financials, trends
10 AI agents analyze the data
Each agent focuses on its specialty: market, competitors, risk, financials, GTM...
Multiple models cross-validate
Same data, different providers, median score selected to eliminate outliers
Score calibrated with real signals
Real competitor count, community demand, and trend data shift the score up or down
15-section report assembled
Every finding linked to its original source so you can verify it yourself
Report delivered
Full report with viability score, competitor map, and action plan
If anything fails mid-pipeline, there are fallbacks at every step. Research gets cached. Failed sections get retried with alternative models. Your report doesn't break because one API had a bad moment. I obsessed over this resilience because I know what it feels like to pay for something that doesn't deliver.
Skip weeks of manual research
Get complete market research, sourced proof, competitor map, and pricing data for your idea instantly.
What's Inside a Deep Analysis Report?
The Deep Analysis produces 15 sections -each one written by a specialized agent with real data. Here's every section and what it covers:
| Section | What You Learn |
|---|---|
| Overview | Quick snapshot: what your idea is, who it's for, and the headline score |
| Validation | Demand signals: are real people actively looking for this solution? |
| Competitors | Real competitors with pricing, features, funding -not hallucinated names |
| Market Sizing | TAM/SAM/SOM estimates with sourced methodology |
| Community Demand | Reddit threads, forum posts, social signals showing organic interest |
| Business Model | Canvas, unit economics, pricing strategy, key assumptions to test |
| Go-to-Market | Launch strategy, growth channels, based on what works in your space |
| Financial Projections | Revenue forecasts, cost estimates, break-even timeline |
| Action Plan | Prioritized next steps: what to do this week, this month, this quarter |
| Tools & Resources | Recommended tools for building, launching, and growing |
| Executive Synthesis | One-page summary: the verdict, the evidence, the risks |
Every finding links back to its source. If the report says your competitor raised $12M, you can click through and see the announcement. If I found a Reddit thread with 200 upvotes asking for exactly what you're building, you can read it yourself. No trust required -verify everything.
Raising capital? The Investor Package ($499) goes even deeper -additional research rounds, investor-ready deliverables, and pitch deck data designed for fundraising conversations.

Every Section Comes With an Investor Lens
This is one of the features I'm most excited about. Every section in the report has two views: the Dashboard (the raw analysis) and the Investor Lens -a VC-style breakdown that evaluates your idea the way a professional investor would.
Click the Investor Lens tab on any section and you get:
- Section verdict -a concise pass/fail assessment with the reasoning behind it
- Key insights -what stands out to a VC reviewing this specific dimension
- Skeptic view -the hard questions an investor would ask about your assumptions
- Next step -the immediate action that would strengthen this part of your case
The Investment Memo and Fundability Radar
On the Overview section, the Investor Lens becomes a full Investment Memo -the kind of document a VC associate would write after doing due diligence. It includes a Fundability Radar: a six-dimension spider chart scoring your idea on Team, Market Size, Product, Competition, Marketing, and Funding Need.
I built this because too many founders pitch investors without knowing how their idea actually scores on the dimensions VCs care about. The Fundability Radar shows you where you're strong and where investors will push back -before you walk into the meeting.
Built-In AI Coach: Don't Just Score Your Idea, Improve It
Most validation tools give you a score and leave you there. I wanted to answer the question every founder asks next: "OK, so how do I make it better?"
After your report is generated, the AI Coach analyzes your score, identifies the single biggest factor dragging it down, and generates targeted pivot suggestions. These aren't generic advice -they're specific strategic moves based on your actual data:
- Zoom In -narrow your focus to a more defensible niche
- Micro-Niche -target an underserved segment competitors are ignoring
- Differentiate -find a positioning angle that separates you from the pack
- Audience Clarity -sharpen who you're building for
- Monetization Shift -rethink your revenue model based on market data
- Adjacent Pivot -shift to a related space with stronger signals
- Wedge Strategy -start smaller to enter a larger market
Pick a suggestion and the pipeline re-runs the entire analysis on your refined idea -same 10 agents, same 50+ sources, new score. You can see exactly how each pivot changes your viability rating.
The results speak for themselves:
The AI Coach identifies what's dragging your score down, suggests concrete moves, and then re-runs the full analysis on your revised idea so you can see exactly what changed. Every pivot recommendation is grounded in the competitive gaps and market data from your report.
How Does This Compare to Other AI Validation Tools?
I'll let the comparison speak for itself:
| Typical AI Tool | Preuve AI | |
|---|---|---|
| AI models | 1 model | Multiple models, cross-validated |
| Data sources | Training data only | 50+ live sources, real-time |
| Analysis agents | 1 prompt | 10 specialized agents |
| Sources cited | None or fabricated | Every claim linked |
| Consistency | Varies wildly per run | Median filtering for stability |
| Competitors | Made-up names | Scraped from real databases |
| Investor view | None | Investment Memo + Investor Lens on every section |
| After the score | Nothing | AI Coach with targeted pivots + re-analysis |
According to CB Insights, 42% of startups fail because there's no market need. That's a research problem, not a technology problem, and it's exactly why I built this. When you're deciding whether to spend the next 6-12 months of your life on an idea, a confident-sounding guess from one AI model is not enough. You need evidence you can actually trace back to a source.
In AI research, this architecture is called a Compound AI System -a term coined by researchers at UC Berkeley (Matei Zaharia et al., 2024). Instead of relying on a single model, it combines multiple specialized components: retrievers, analyzers, validators, and synthesizers working together. That's exactly what I built.
I published the full data in the early-2026 study of 1,000+ startup ideas. The pattern is clear: the difference between a score of 48 and 72 isn't a better idea. It's better research. And that's what this pipeline delivers.
Ready to See What 10 AI Agents Think of Your Idea?
The free scan gives you a taste: overview, basic validation, and a competitor snapshot. The Deep Analysis ($29) runs the full 10-agent pipeline with all 50+ sources and cross-validation.
Either way, every finding links to its source. No hallucinations, no invented competitors, no round numbers that came from nowhere.
Free scan in 60 seconds. No signup required.
FAQ
Is Preuve AI just using ChatGPT?
No. I built Preuve AI on multiple AI models from different providers, cross-validated against each other. The pipeline runs parallel analyses on the same data and takes the median result to filter outliers. The AI analyzes real data pulled from 50+ live sources, not just training data.
How many AI models does Preuve AI use?
The Deep Analysis runs multiple AI models from different providers simultaneously. Each model analyzes the same research data independently. The pipeline then selects the median score to eliminate outliers and hallucinations. This ensemble approach is far more reliable than any single model.
What data sources does the Deep Analysis pull from?
Over 50 live sources including competitor databases (G2, Capterra, Product Hunt, Alternative.to), community forums (Reddit, Indie Hackers, Hacker News, Quora), financial databases for funding and revenue data, and real-time search trends. Every finding links back to its source.
How long does a Deep Analysis take?
About 6 minutes. The system runs 10 specialized agents, 50+ data source queries, and cross-validates across multiple AI models. That thoroughness takes time, but every minute is spent pulling real data and cross-checking results. Research is cached so if any step fails, the system resumes from the last checkpoint.
What's the difference between the free scan and Deep Analysis?
The free scan gives you an overview, basic validation, and a limited competitor list. The Deep Analysis ($29) runs all 10 agents across 50+ sources with multi-model cross-validation, producing 15 detailed sections including market sizing, financial projections, community demand signals, and an executive synthesis. Need investor-grade research? The Investor Package ($499) adds deeper analysis and pitch-ready deliverables.
How do you prevent AI hallucinations in the reports?
Three safeguards: First, the AI analyzes real data fetched from live sources, not its own training data. Second, the pipeline cross-validates across multiple models and takes the median to filter outliers. Third, every claim in the report links to the original source so you can verify it yourself.
Vincent
5 years in B2B growth, building Preuve AI in public. 82% of ideas it scores aren't ready, the point is finding out in 8 minutes, not 3 months.
Follow on X →

